KMP: 정확히 똑같은 것을 찾는다.
근사문자열 매칭
검색엔진의 유사어 추천 기능
거리함수
비슷하다는 정의는 여러개 있다. 정의가 복잡할 수록 현실과 가깝다.
- 해밍거리 change
ababc
abbc
같은 자리끼리 비교한다. 다른 정도가 3 (스코어가 클 수록 먼 것)
옛날 통신에서 글자가 밀리는 일은 없지만 글자가 바뀔 수는 있다면 의미 있는 방법
- 편집거리
change,insert,delete
글자가 추가/삭제되어 올 수도 있음.
abc def 와 def abc는 매우 달라진다.
- 가중편집거리
change,insert,delete
a가 s가 되는 것과 a가 p가 되는 것에 대한 가중치가 다르다. 오타 커버 가능
- 기타
block단위
편집거리
한 문자열을 다른 문자열로 변경하기 위해 필요한 편집연산들의 최소 수

모든 쌍들에 대해 s1의 몇글자와 s2의 몇글자의 편집거리를 계산한다.
계산하는 값의 갯수 = (n+1)x(m+1)개

이미 계산한 값을 이용해서 계산한다.

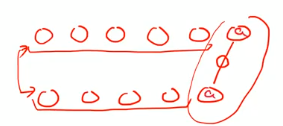
1. 마지막 두 문자가 match된다면 (match)
마지막 부분을 제외하고 앞 부분을 따로 풀 수 있다.
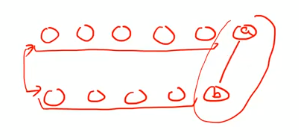
2. 이 경우는 다르기 때문에 change를 고려해야 한다. (mismatch)

3. a는 빠지기로 정하고 앞의 부분을 match시킨다. (delete)
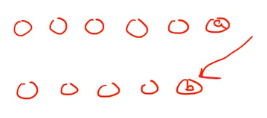
4. b가 추가되는 경우 (insert)
=>4가지 중 각각 제일 좋은 값을 찾고 그 중에 제일 좋은 경우를 찾는다.

operation은 1차원으로 (한출로) 설명가능 -> 마지막 operation 이 뭔지 말할 수 있다.

4개 중에 제일 좋은 것이 전체에서 가장 좋은 것!
match와 change는 동시에 일어날 수 없다. (마지막 글자가 같을 떄, 다를 때)

그래서 식은 3개이다.
D(n,m) => 답 but 엄청느리다. 계속 3개씩 계산해야 한다.
재사용이 되므로 다이나믹 프로그래밍이 된다.
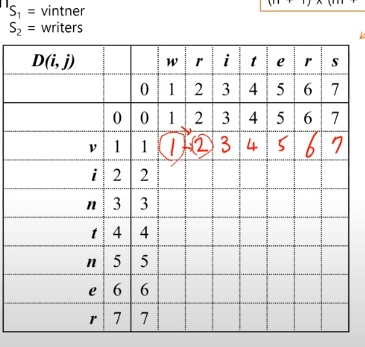
v는 S2에서 같은 글자가 하나도 없음

nxm 시간
'알고리즘' 카테고리의 다른 글
| 알고리즘18 다이나믹 프로그래밍 마지막 (0) | 2020.10.29 |
|---|---|
| 알고리즘17-2 최장 공통 부분 서열(LCS) (0) | 2020.10.29 |
| 알고리즘 16-2 (0) | 2020.10.25 |
| 알고리즘16-1 (0) | 2020.10.25 |
| 알고리즘15-2 (0) | 2020.10.25 |



